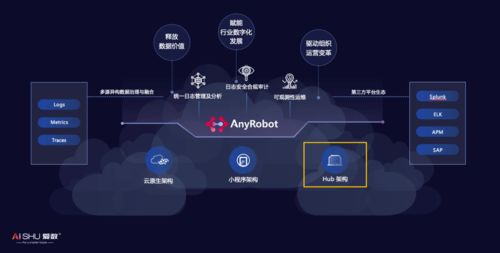
在數(shù)字化轉(zhuǎn)型浪潮席卷全球的當下,企業(yè)數(shù)據(jù)量呈指數(shù)級增長,運維數(shù)據(jù)的復雜性、多樣性和實時性要求日益提升。傳統(tǒng)的單一、孤島式的運維數(shù)據(jù)分析平臺已難以滿足現(xiàn)代企業(yè)對于統(tǒng)一監(jiān)控、智能分析和快速響應的需求。愛數(shù)AnyRobot作為領先的智能運維與可觀測性平臺,近期基于創(chuàng)新的Hub(中心樞紐)架構(gòu),實現(xiàn)了對Splunk數(shù)據(jù)的有效納管與融合處理,標志著運維數(shù)據(jù)處理范式的一次重要革新,為企業(yè)構(gòu)建統(tǒng)一、智能的數(shù)據(jù)運維中心提供了強大引擎。
一、 挑戰(zhàn)與機遇:為何需要納管Splunk數(shù)據(jù)?
Splunk作為早期進入市場的機器數(shù)據(jù)分析平臺,在全球范圍內(nèi)擁有廣泛的企業(yè)用戶基礎,積累了海量的歷史日志、指標和事件數(shù)據(jù)。這些數(shù)據(jù)是企業(yè)IT環(huán)境健康狀況、安全態(tài)勢和業(yè)務運行情況的寶貴記錄。隨著技術棧的多元化(云原生、微服務、容器化)和成本優(yōu)化需求的增長,企業(yè)往往面臨以下挑戰(zhàn):
- 成本高企:Splunk的許可模式隨著數(shù)據(jù)量增長而成本陡增。
- 架構(gòu)局限:傳統(tǒng)架構(gòu)在應對超大規(guī)模、實時流式數(shù)據(jù)處理時可能存在彈性與效率瓶頸。
- 生態(tài)融合難:與企業(yè)內(nèi)部新興的觀測數(shù)據(jù)源、國產(chǎn)化平臺或特定場景分析工具集成復雜,易形成新的數(shù)據(jù)孤島。
因此,在不拋棄歷史數(shù)據(jù)資產(chǎn)的前提下,尋求一個更開放、更具性價比、處理能力更強的統(tǒng)一平臺來納管并深度利用這些數(shù)據(jù),成為眾多企業(yè)的迫切需求。愛數(shù)AnyRobot的Hub架構(gòu)正是為此而生。
二、 核心創(chuàng)新:Hub架構(gòu)的解耦與協(xié)同優(yōu)勢
AnyRobot的Hub架構(gòu)設計精髓在于“解耦”與“協(xié)同”。它將數(shù)據(jù)采集、數(shù)據(jù)處理、數(shù)據(jù)存儲和數(shù)據(jù)分析等核心能力模塊化,并通過統(tǒng)一的中心樞紐進行調(diào)度和管理。在納管Splunk數(shù)據(jù)的場景下,這一架構(gòu)展現(xiàn)出獨特優(yōu)勢:
- 統(tǒng)一接入與納管:Hub作為中心調(diào)度點,可以無縫接入來自Splunk的歷史數(shù)據(jù)(通過API、文件導出等方式)以及實時數(shù)據(jù)流。它打破了源端系統(tǒng)的邊界,將Splunk數(shù)據(jù)與其他數(shù)據(jù)源(如APM、NPM、基礎設施監(jiān)控、業(yè)務日志等)置于同一套管理框架下。
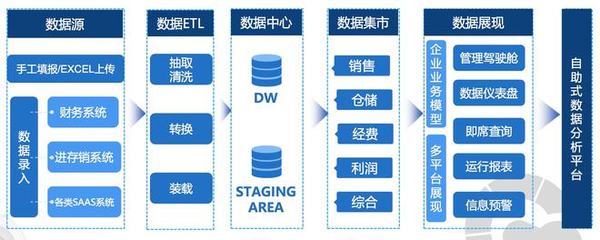
- 數(shù)據(jù)處理流水線化:納管后的數(shù)據(jù)進入AnyRobot強大的數(shù)據(jù)處理流水線。Hub架構(gòu)允許動態(tài)配置數(shù)據(jù)解析、清洗、豐富、脫敏、歸一化等處理規(guī)則。例如,將Splunk中的原始日志格式與來自其他系統(tǒng)的日志進行字段統(tǒng)一,為后續(xù)的關聯(lián)分析奠定基礎。
- 彈性存儲與計算分離:得益于架構(gòu)解耦,AnyRobot可以采用更具成本效益的存儲方案(如對象存儲)來長期歸檔海量Splunk歷史數(shù)據(jù),同時利用高性能的索引存儲滿足熱數(shù)據(jù)的快速檢索。計算資源也可以根據(jù)分析任務的需求獨立彈性伸縮,克服了傳統(tǒng)一體架構(gòu)的資源爭用問題。
- 智能分析能力注入:Hub將納管的數(shù)據(jù)統(tǒng)一輸送至AnyRobot的智能分析引擎。這意味著原本在Splunk中的數(shù)據(jù),現(xiàn)在可以輕松利用AnyRobot內(nèi)置的機器學習算法進行異常檢測、根因分析、趨勢預測,或與可觀測性數(shù)據(jù)進行全鏈路追蹤關聯(lián),獲得更深入的洞察。
三、 實踐路徑:如何實現(xiàn)平滑納管與數(shù)據(jù)處理
愛數(shù)AnyRobot納管Splunk數(shù)據(jù)并非簡單的數(shù)據(jù)遷移,而是一個循序漸進的融合過程:
- 評估與規(guī)劃階段:分析現(xiàn)有Splunk的數(shù)據(jù)類型、量級、訪問頻率及關鍵用例。確定首批納管的數(shù)據(jù)范圍(如核心應用日志、安全事件日志)和納管模式(全量歷史遷移+增量實時同步,或僅同步增量數(shù)據(jù))。
- 連接與接入階段:利用AnyRobot Hub提供的豐富連接器或自定義接口,建立與Splunk實例的安全連接。配置數(shù)據(jù)拉取或接收策略,確保數(shù)據(jù)持續(xù)、穩(wěn)定地流入AnyRobot平臺。
- 數(shù)據(jù)處理與建模階段:在AnyRobot中針對納管的Splunk數(shù)據(jù)定義解析規(guī)則(Parsing),提取關鍵字段。建立統(tǒng)一的數(shù)據(jù)模型(Schema),將Splunk事件字段映射到企業(yè)通用的運維數(shù)據(jù)模型中,實現(xiàn)與來自其他源的數(shù)據(jù)的“同聲翻譯”。
- 融合分析與價值釋放階段:基于統(tǒng)一的數(shù)據(jù)湖,運維團隊可以:
- 進行跨源關聯(lián)分析:將一個來自Splunk的應用程序錯誤日志,與來自APM的代碼級性能指標、來自基礎設施的服務器資源利用率進行時間序列關聯(lián),快速定位根因。
- 應用智能告警:利用AnyRobot的機器學習,對納管的Splunk數(shù)據(jù)流建立動態(tài)基線,實現(xiàn)比傳統(tǒng)閾值告警更精準、更提前的異常預警。
- 構(gòu)建統(tǒng)一儀表盤:在單一玻璃面板上,同時展現(xiàn)源自Splunk的歷史趨勢圖與當前其他系統(tǒng)的實時狀態(tài),形成完整的業(yè)務服務視圖。
- 優(yōu)化成本與歸檔:將訪問頻次低的Splunk歷史數(shù)據(jù)自動沉降至低成本存儲,同時保持可檢索性,顯著降低總體擁有成本(TCO)。
四、 未來展望:構(gòu)建面向未來的智能運維數(shù)據(jù)生態(tài)
愛數(shù)AnyRobot基于Hub架構(gòu)納管Splunk,其意義遠超一個數(shù)據(jù)遷移項目。它代表了一種以數(shù)據(jù)為中心、開放融合的智能運維新思路:
- 保護歷史投資:尊重并最大化利用現(xiàn)有數(shù)據(jù)資產(chǎn)。
- 擁抱開放生態(tài):通過Hub架構(gòu),AnyRobot未來可以同樣優(yōu)雅地納管各類異構(gòu)數(shù)據(jù)源,成為企業(yè)真正的運維數(shù)據(jù)“集線器”。
- 驅(qū)動持續(xù)智能:統(tǒng)一的數(shù)據(jù)基礎是高級AIOps應用(如自動根因定位、預測性維護)的燃料,賦能運維從“被動響應”走向“主動預防”和“自主修復”。
愛數(shù)AnyRobot通過Hub架構(gòu)創(chuàng)新性地解決Splunk數(shù)據(jù)納管難題,不僅為企業(yè)提供了平滑的演進路徑和顯著的成本效益,更重要的是,它為企業(yè)搭建了一個面向未來、彈性靈活、智能驅(qū)動的統(tǒng)一運維數(shù)據(jù)分析平臺,助力企業(yè)在數(shù)字化競爭中贏得先機。